These following pictures show results obtained from running the
blocksearch.py script of my code generator.
The pictures shows different combination of unrolling of the innermost
loop and the blocking size used in atlas. There is no use of
prefetching. The same kind of register blockings is used for all
cases. This is usually ok, since the register blockings is mostly
independent of the loop unrollings.
The results have been obtained using atlas' kernel testers. This means
that the information displayed of the graphs does not necessarily
translate to a full kernel build. Often, a small block size will be
preferable, as it reduces the need for cleanup.
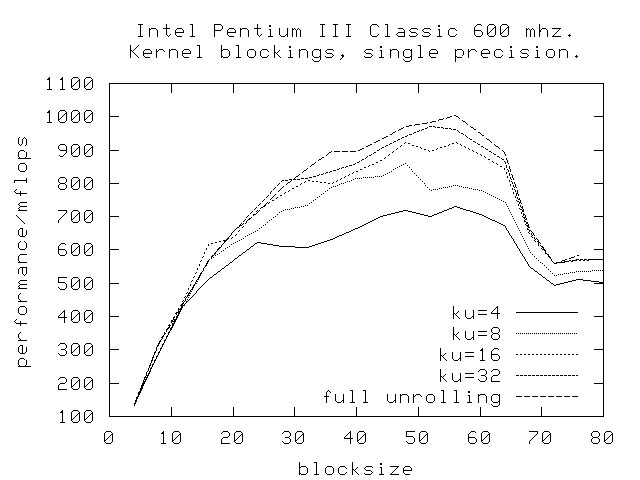
The first picture shows results for a Pentium 3. Notice the drop-off
in perfomance when the L1 cache is exceeded at at block size of 64.
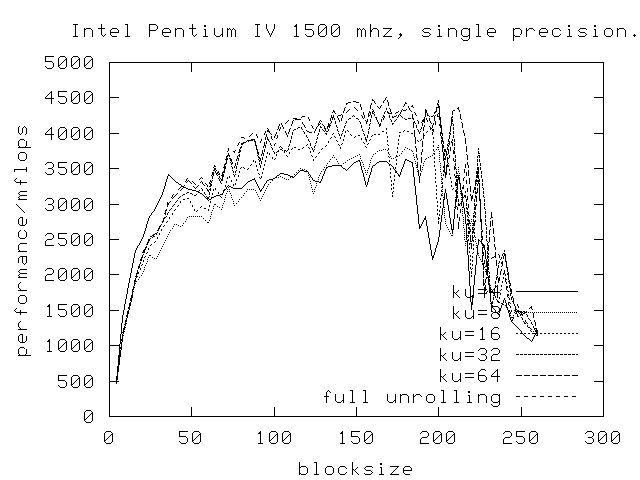
This picture shows results for a Pentium 4 computing in double precision.
The drop-off in performance is more level here. Notice the big dip at
a blocksize of 128, this is probably due to some aliasing issues in
the cache. Another interesing feature (hard to see) is that a loop
unrolling of 8 is the fastest, and not the full loop unrolling. This
is probably the benefit of the trace-cache that makes this possible.
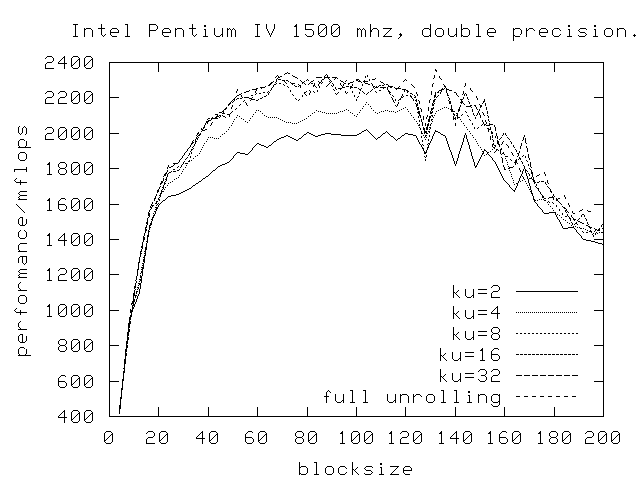
The same picture just for single precision.